LM StudioでローカルのMacbookProでqwen2.5-coderを動かした。Codexからも使える
今日はローカルLLMを動かしていた。
https://qwen.ai/blog?id=qwen3-coder-nextを見かけて、qwen3-coder-nextがめっちゃ性能いいらしいとなり、量子化すれば動くのかなと思いいろいろ調べていた。
私もマシンはM4 MacbookProの48GBメモリで、動かすくらいはできそうだとなり、LM Studioをインストールしてモデルをダウンロードして動かしてみた。
ローカルLLMは1年ぐらい前に試したが遅すぎるしごくごく基本的なことしかできないので実用には遠いなと思っていたが、今回試したら十分実用的で驚いた。
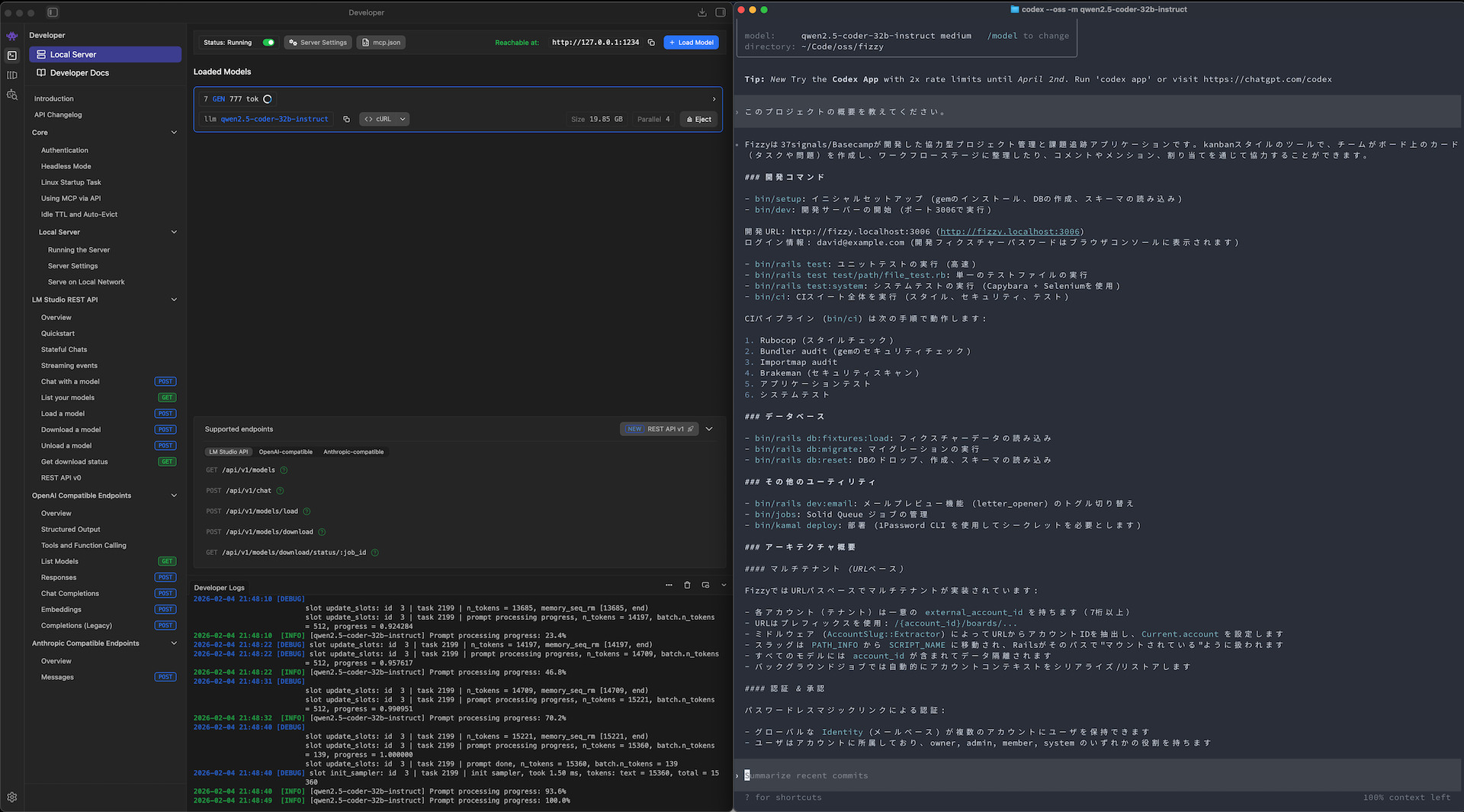
やったことはLM Studioをインストールして、アプリを起動するとの中でモデルを検索できるので、qwen2.5とかqwen3あたりで探してダウンロード数が多いものを入れた(一応そのモデルの提供元は確認した)。LM Studioは親切でローカルマシンのスペックをみてこれは動かなそうというモデルは「Likely too large」と赤く表示してくれるので、その警告がないなかで良さげなものをダウンロードした。今回試したのは以下の2つ。
- qwen2.5-coder-32b-instruct(19.85 GB)
- qwen3-coder-next(29.15GB)
普通にダウロード可能なサイズであることがわかる。ダウンロードも早くてどちらも十数分で終わって、まずチャットインタフェースで動かしてみた。
qwen3のほうは残念ながらかなり重くてローカルで動かすのは辛いので早々に諦めた。
qwen2.5のほうは少しだけ遅さは感じるものの、実用的な速度で出力してくれる。日本語も使えるし、Ruby on Railsの基本知識も持っている。
Codexからも動かせた。公式ドキュメントがあるのでそれにそってやるだけで動かせた。
ローカルでここまで動くんだと感動した。これはすごい
もちろん現時点ではクラウドのトップレベルのLLMには劣るが、「これで十分」と感じるレベルに到達するのは遠くない未来のように思った。
いまはクラウドのLLMを使うのが当たり前だが、ローカルで賄える時代はそう遠くない未来に来ると思う。全てがローカルにはならないかもだけど、少なくともハイブリッドにはなる。
いまは例えばclaude maxプラン使ってもレートリミットかかれば使えないが、ローカルなら勝手に制限かかることはない。電気代はかかるけどそれ以外は動き続けてくれる。
メモリ48GBだと快適に動かすには足りない。LLMは実用的な速度で動くようになったとしても、別のプロセスが影響受けてかなり重くなってしまう。
ローカルLLM用としてデスクトップマシンほしくなってきた。 2台持ちにして1台はLLM用っていう構成を取れば実用性ある気がする。